Open Source Data Engineering Landscape 2024
The original post was published on Practical Data Engineering Substack
Introduction
While the widespread hype surrounding Generative AI and ChatGPT took the tech world by storm, 2023 witnessed yet another exciting and vibrant year in the data engineering landscape, steadily grown more diverse and sophisticated, with continuous innovation and evolution across all tiers of the analytical hierarchy.
With the continued proliferation of open source tools, frameworks, and solutions, the options available to data engineers have multiplied! In such rapidly changing landscape, the importance of staying abreast of the latest technologies and trends cannot be overstated. The ability to choose the right tool for the right job is a crucial skill, ensuring efficiency and relevance in the face of evolving data engineering challenges.
Having closely followed data engineering trends in my role as a senior data engineer and consultant, I’d like to present the open source data engineering landscape at the beginning of 2024. This includes identifying key active projects and prominent tools, empowering readers to make informed decisions when navigating this dynamic technological landscape.
Why Present Another Landscape?
Why make the effort to present yet another data landscape!? There are similar periodic reports such as the famous MAD Landscape , State of Data Engineering and Reppoint Open Source Top 25, however the landscape I’m presenting is focused solely on open source tools mainly applicable to data platforms and data engineering lifecycle.
The MAD Landscape provides a very comprehensive view of all tools and services for Machine Learning, AI and Data, including both commercial and open source, while the landscape presented here provides a more comprehensive view of active open source projects in the Data part of MAD. Other reports such as Reppoint Open Source Top 25 and Data50 focus more on the SaaS providers and startups, whereas this report focuses on the open source projects themselves, rather than the SaaS services.
Annual reports and surveys such as Github’s state of open source , Stackoverflow annual survey and OSS Insight reports are also great sources for gaining insight into what’s being used or trending in the community, but they only cover limited sections (such as databases and languages) of the overall data landscape.
Therefore due to my interest in open source data stacks, I’ve compiled the open source tools and services in data engineering ecosystem.
So without further due, here is the 2024 Open Source Data Engineering Ecosystem:

Tool Selection Criteria
The available open source projects for each category are obviously vast, making it impractical to include every tool and service in the picture. Therefore I have followed the following criteria for selecting the tools for each category:
- Any retired, archived and abandoned projects are excluded. Some notable retired projects are Apache Sqoop, Scribe and Apache Apex which might still be used in some production environments.
- Projects which have been completely inactive on Github over the past year, and are hardly mentioned in the community are excluded. Notable examples are Apache Pig and Apache Oozie projects.
- Projects which are still quite new and have not gained much traction in terms of Github stars, forks, as well as blog posts, show cases and mentions in the online communities, are excluded. However some promising projects such as OneTable which has made some notable traction and are implemented on the foundation of existing technologies are mentioned.
- Data Science, ML and AI tools are excluded, except for ML platform and infrastructure tools, as I’m only focusing on what’s related to data engineering discipline.
- Different types of storage systems such as relational OLTP and embedded database systems are listed. This is because data engineering discipline involves dealing with many different internal and external storage systems used in applications and operational systems (BSS), even if they are not part of the analytics stack.
- The category names are chosen as generic as possible based on where the tool fits in the data stack. For storage systems, main database model and database workload (OLTP, OLAP) are used for grouping and labeling the systems, but for instance “Distributed SQL DBMS” are also referred to as HTAP or scalable SQL databases in the market.
- Some tools could belong to more than one category. VoltDB is both an in-memory database and distributed SQL DBMS. But I have tried to place them in the category by which they are mostly recognised in the market.
- For certain database systems, there may be a blurry line regarding the category they actually belong to. For example ByConity claims to be a data warehousing solution, but is built on top of ClickHouse which is recognised as a Real-time OLAP engine. Therefore it is still unclear whether it is real-time (ability to support sub-second queries) OLAP system or not.
- Not all the listed projects are fully Portable open source tools. Some of the projects are rather Open Core than open source. In open core models, not all components of the full system, as offered by the main SaaS provider, are made open source. Therefore, when deciding to adopt an open-source tool, it is important to consider how portable and truly open source the project is.
Overview of Tool Categories
In the following section each category is briefly discussed.
1. Storage Systems
Storage systems are the largest category in the presented landscape, primarily due to the recent surge of specialized database systems. Two latest trending categories are vector and streaming databases. Materialize and RaisingWave are examples of open-source streaming database systems. Vector databases are also experiencing rapid growth in the storage systems field. I have placed vector storage systems in the ML Platform section since they are primarily used in ML and AI stacks. Distributed file systems and object stores are also placed their own related category, that is Data Lake Platform.
As mentioned in the selection criteria section, storage systems are grouped and labeled based on the main database model and workload. At the highest level, storage systems can be classified into three main classes: OLTP, OLAP, and HTAP. They can be further categorized based on SQL vs NoSQL for OLTP engines, and Offline (non-real-time) vs Real-time (sub-seconds result) for OLAP engines, as shown in the following figure.
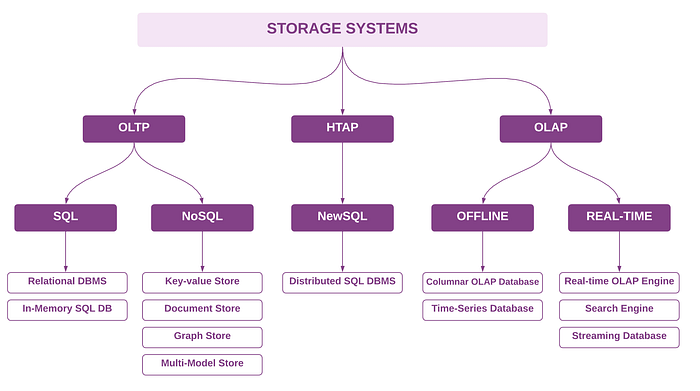
2. Data Lake Platform
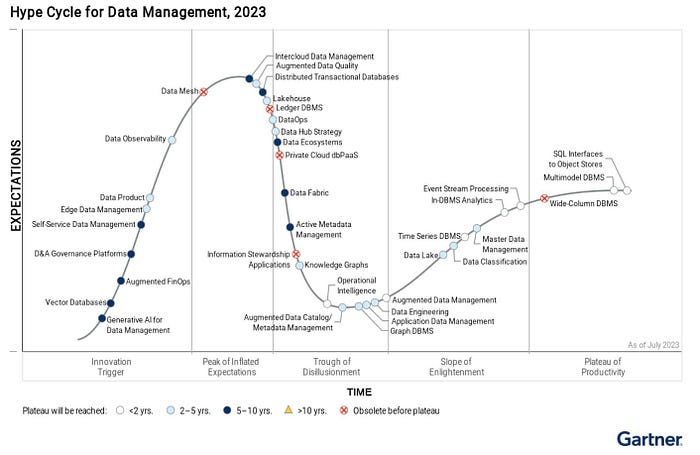
Data Lake platform has continued to mature in the past year, and Gartner has placed Data Lake in the slope of enlightenment in its 2023 edition of Hype Cycle for Data Management.
For storage layer, distributed file systems and object stores are still the main technologies serving as the bedrock for both on-premise and cloud-based data lake implementations. While HDFS is still the primary technology used for on-premise Hadoop clusters, Apache Ozone distributed object store is catching up to provide an alternative on-premise data lake storage technology. Cloudera, the main commercial Hadoop provider, is now offering Ozone as part of its CDP Private Cloud offering.
The choice of data serialization format impacts storage efficiency and processing performance. Apache ORC remains the preferred choice for columnar storage within Hadoop ecosystems, while Apache Parquet has emerged as the de-facto standard for data serialization in modern Data Lakes. Its popularity stems from its compact size, efficient compression, and wide compatibility with various processing engines.
Another key trend in 2023 is the decoupling of storage and compute layers. Many storage systems now offer integration with cloud-based object storage solutions like S3, leveraging their inherent efficiency and elasticity. This approach allows data processing resources to scale independently from storage, leading to cost savings and enhanced scalability. Cockroachdb supporting S3 as storage backend, and Confluent’s offering of long-term Kafka topic data retention on S3 further exemplifies this trend, highlighting the growing use of data lakes as cost-effective, long-term storage solutions.
One of the hottest developments in 2023 was the rise of open table formats. These frameworks essentially act as a table abstraction and virtual data management layer sitting atop your data lake storage and data layer as depicted in the following diagram.
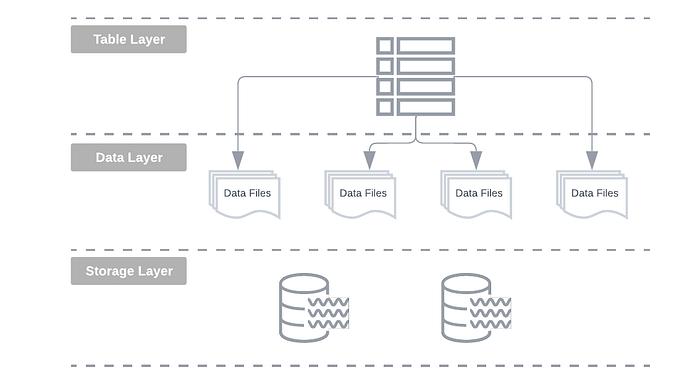
The open table format space is currently dominated by a fierce battle for supremacy between the following three major contenders:
- Apache Hudi: Initially developed and open-sourced by Uber, with main design goal for near-real-time data updates and ACID transactions.
- Apache Iceberg: Born from Netflix’s engineering team.
- Delta Lake: Created and open-sourced by Databricks, with seamless integration with the Databricks platform.
The funding received by the leading SaaS providers in this space in 2023 — Databricks, Tabular, and OneHouse — emphasises market interest and their potential to further advance data management on data lakes.
Moreover, a new trend is now unfolding with the emergence of unified data lakehouse layers. OneTable (recently open-sourced by OneHouse) and UniForm (currently non-open source offering from Databricks) are the first two projects which were announced last year. These tools go beyond individual table formats, offering the ability to work with all three major contenders under a single umbrella. This empowers users to embrace a universal format while exposing data to processing engines in their preferred formats, leading to increased flexibility and agility.
3. Data Integration
The data integration landscape in 2023 witnessed not only continued dominance from established players like Apache Nifi, Airbyte, and Meltano, but also the emergence of promising tools like Apache Inlong and Apache SeaTunnel offering compelling alternatives with their unique strengths.
Meanwhile, Streaming CDC (Change Data Capture) has further matured, fueled by active development in the Kafka ecosystem. Kafka Connect and Debezium plugins have become go-to choices for near real-time data capture from database systems, while Flink CDC Connectors are gaining traction for deployments using Flink as the primary stream processing engine.
Beyond traditional databases, tools like CloudQuery and Streampipe are simplifying data integration from APIs, providing convenient solutions for ingesting data from diverse sources. which reflects the growing importance of flexible integration with cloud-based services.
In the realm of event and messaging middlewares, Apache Kafka maintains its strong position, though challengers like Redpanda are closing the gap. Redpanda’s $100 million Series C funding in 2023 shows the growing interest in alternative message brokers offering low latency and high throughput.
4. Data Processing & Computation
The world of Stream processing continued to heat up in 2023! Apache Spark and Apache Flink remain the reigning champions, however Apache Flink made some serious headlines in 2023. Cloud giants like AWS and Alibaba jumping on board with Flink-as-a-service offerings, and Confluent’s acquisition of Immerok for its own fully managed Flink as a service offering, show the momentum behind this powerful engine.
In the Python ecosystem, data processing libraries such as Vaex, Dask, polars, and Ray are available for exploiting multi-core processors. These parallel execution libraries further unlock possibilities for analysing massive datasets within the familiar Python environment.
5. Workflow Management & DataOps
The workflow orchestration landscape is arguably the most packed category in presented data ecosystem, filled with established heavyweights and exciting newcomers.
Veteran tools such as Apache Airflow and Dagster are still going strong and remains a widely used engines amid the recent hot debates in the community on unbundling, rebundling and bundling vs unbundling of workflow orchestration engines. On the other hand In the past two years, GitHub has witnessed the rise of several compelling contenders, capturing significant traction. Kestra, Temporal, Mage, and Windmill are all worth watching, each offering unique strengths. Whether focusing on serverless orchestration like Temporal, or distributed task execution like Mage, these newcomers can cater to the evolving needs of modern data pipelines.
6. Data Infrastructure & Monitoring
The recent Grafana Labs Survey, confirms Grafana, Prometheus and ELK stack continue to dominate the observability and monitoring landscape. Grafana Labs itself has been quite active, introducing new open-source tools like Loki (for log aggregation) and Mimir (for long-term Prometheus storage) to further strengthen its platform.
One area where open-source tools seem less prevalent is cluster management and monitoring. This likely stems from the cloud migration trend, reducing the need for managing large on-premise data platforms. While the Apache Ambari project, once popular for managing Hadoop clusters, was practically abandoned after the Hortonworks-Cloudera merger in 2019, a recent revival sparks some hope for its future. However, its long-term fate remains uncertain.
As for resource scheduling and workload deployment, Kubernetes seems to be the preferred resource scheduling specially on cloud-based platforms.
7. ML Platform
Machine Learning Platform has been one of the most active categories with unprecedented rise and interest in Vector databases, specialised systems optimised for the storage and retrieval of high-dimensional data. As highlighted by DB-Engines’ 2023 report, vector databases emerged as the most popular database category in the past year.
MLOps tools also play an increasingly vital role in scaling ML projects efficiently, ensuring smooth operations and ML application lifecycle management. As the complexity and scale of ML deployments continue to grow, MLOps tools have become indispensable for streamlining development, deployment, and monitoring of ML models.
8. Metadata Management
In recent years, metadata management has taken center stage, propelled by the growing need to govern and improve management and access to data. However, the lack of comprehensive metadata management platforms prompted tech giants like Netflix, Lyft, Airbnb, Twitter, LinkedIn and Paypal to build their own solutions.
These efforts yielded some remarkable contributions to the open-source community. Tools like Amundsen (from Lyft), DataHub (from LinkedIn), and Marquez (from WeWork) are homegrown solutions, which have been open sourced and are under active development and contribution.
When it comes to schema management, the landscape remains somewhat stagnant. Hive Metastore continues to be the go-to solution for many as there are currently no alternative open source solution to replace it.
9. Analytics & Visualisation
In the Business Intelligence (BI) and visualisation domain, Apache Superset stands out as the most active and popular open-source alternative to licensed SaaS BI solutions.
As for distributed and Massive Parallel Processing (MPP) engines, some experts argue that big data is dead and majority companies don’t require large-scale distributed processing, opting for single, powerful servers to handle their data volumes.
Despite this claim, distributed Massively Parallel Processing (MPP) engines like Apache Hive, Impala, Presto and Trino remain prevalent within large data platforms, especially for petabyte-scale data.
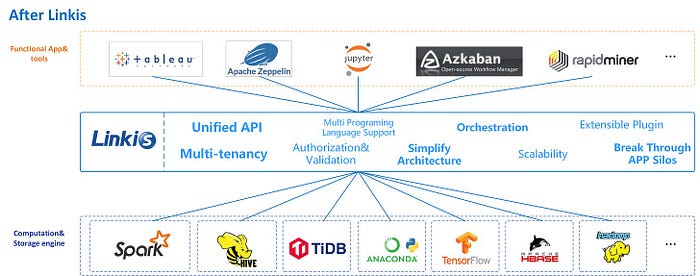
Beyond traditional MPP engines, uniform execution engines are another trend gaining traction. Engines such as Apache Linkis, Alluxio and Cube provide a query and computation middleware between upper applications and underlying engines.
Conclusion
This exploration of the open-source data engineering landscape is a glimpse into the dynamic and vibrant world of data platforms. While prominent tools and technologies were covered across various categories, the ecosystem continues to evolve rapidly, with new solutions emerging continuously.
Remember, this is not an exhaustive list, and the “best” tools are ultimately determined by your specific needs and use cases. Feel free to share any notable tools I’ve missed that you think should’ve be included.
Update:
I’ve created a live repository on Github with the full list and link to all listed projects. Please feel free to track and contribute.
The original post was published on Practical Data Engineering Substack
