Building a High-Performance Data Pipeline Using DuckDB
The original article was published on my Practical Data Engineering Newsletter.
DuckDB, a high-performance, embeddable analytical engine, has been generating a lot of interest due to its lightweight setup and powerful capabilities.
In a recent article, DuckDB Beyond the Hype, I explored its various use cases and briefly demonstrated how it can be used in data engineering and data science workflows.
One use case that particularly resonated with readers was using DuckDB for data transformation and serialisation on data lakes. Inspired by some readers feedback, I decided to write this follow-up article to dive deeper into this use case and provide a full code example.
In this article, I present a high-level use case with sample code, demonstrating how to move data between different zones in a data lake, using DuckDB as the compute engine.
To keep the focus on the core concepts, only brief code snippets are included, but the full implementation can be found on GitHub for those who want to dive deeper.
Project Overview
For simplicity, I implemented the project as a pure Python application, with minimal dependencies. The only external dependency is a cloud object store for our data lake implementation, which doesn’t have to be AWS S3 specifically — it can be any S3-compatible object store. Alternatively, you can use LocalStack to emulate the data lake locally on your machine.
The use case we’ll be exploring involves incrementally collecting the GitHub Archive datasets, which provide a full record of GitHub activities for public repositories, and enabling analytics on top of that data.
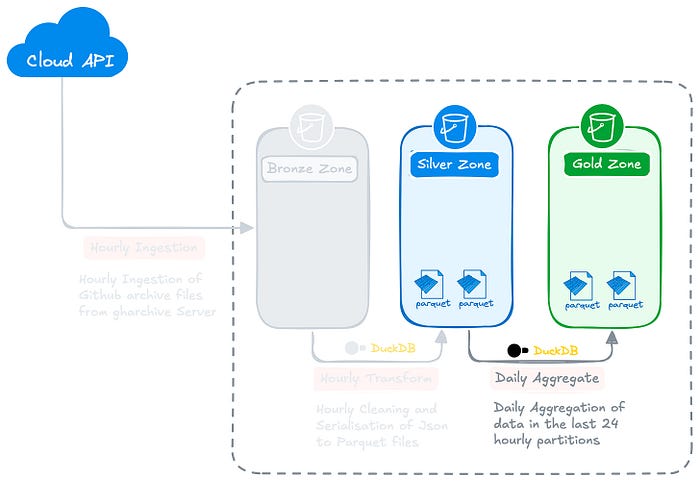
Data Lake Architecture
We will a multi-tier architecture, also referred to as Medallion architecture for this exercise. The Medallion architecture is a data lake design pattern that organises data into three zones:
- Bronze Zone: Containing raw, unprocessed data ingested from various sources.
- Silver Zone: Containing cleaned, conformed and potentially modeled data.
- Gold Zone: Containing aggregated and curated data ready for reporting, dashboards, and advanced analytics.

By maintaining this multi-zone architecture (Bronze → Silver → Gold), we ensure access to data at various stages of processing — ranging from raw data for detailed analysis to aggregated data for quick insights. This flexibility allows us to meet a wide range of analytical needs while optimising for both storage and query performance.
Partitioning Scheme
Each zone will use an appropriate partitioning scheme to optimise data ingestion, query performance and improve overall efficiency.
Typically, the partitioning scheme aligns with the data ingestion and transformation frequency for batch workloads. This approach ensures that the pipeline remains deterministic at the partition level.
In other words, there are no overlaps between individual job runs, and if a pipeline fails or an anomaly is detected in the data, we can safely rerun the job for that specific period. The pipeline will replace the affected partition and its contents, avoiding any negative side effects, data duplication or inconsistencies.
This approach is often referred to as functional data processing using immutable partitions. It was popularised by Maxim Beauchemen, who introduced this powerful data engineering pattern in a highly regarded blog post back in 2018.
Following the functional data processing pattern, we’ll ingest data hourly from the source and partition it by both day and hour in the Bronze Zone. Each hourly job writes atomically to its designated partition, ensuring data integrity at this level of granularity.

We’ll apply the same partitioning strategy in the Silver Zone, since the transformation from Bronze to Silver will also run on an hourly basis.
In the Gold Zone, partitioning will be done only by day, since the aggregation job runs on daily internal. The daily job will produce results for the previous day’s data from the Silver Zone.
This approach strikes the right balance between performance and storage — using fine-grained partitions in the early stages and higher-level aggregation in the final layer.
The overall partitioning scheme for the three zones is illustrated in the figure below.
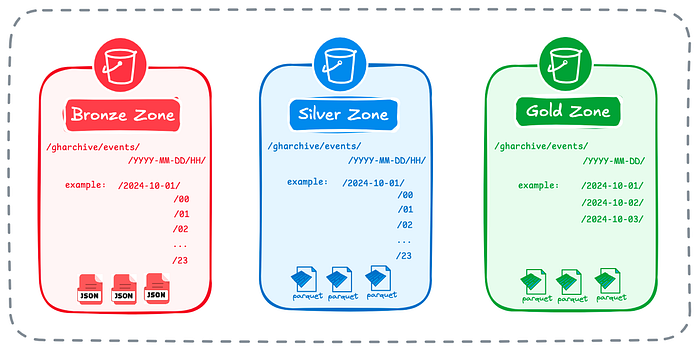
Data Pipeline Architecture
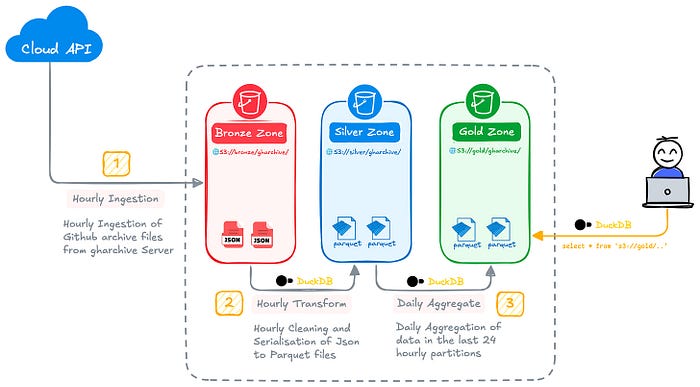
The end-to-end data pipeline is broken down into three key steps:
Step #1 — Ingest the hourly GitHub Archive batch dataset from the gharchive.org website over HTTP and load it into the Bronze Zone of our data lake.
Step #2 — Run an hourly transformation pipeline to clean and serialise the JSON files which loads the results into the Silver Zone.
Step #3 — Run a daily transformation pipeline to aggregate the data from the previous day and store it in the Gold Zone.
Thanks for reading Practical Data Engineering! Subscribe for free to receive new posts and support my work.
Data Source Exploration
Before we jump into building our data pipeline, we should explore and learn about the data source, its characteristics and the shape of data.
A great way for data exploration is using Jupyter. DuckDB can help with exploring the remote data without having to download the entire dataset locally.
The source data are available from gharchive.org and the data dumps are made available on different intervals such as hourly and daily.
The following example demonstrates how to analyse a sample gharchive dump file using DuckDB. With DuckDB, you can define a virtual table directly over a URL, enabling you to query and analyse the data without the need to download the file locally first.
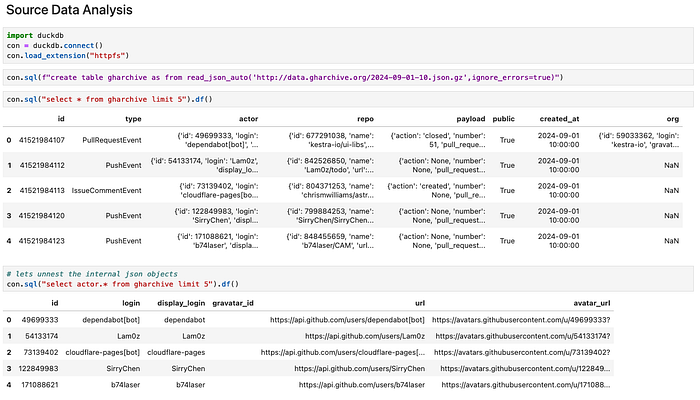
Data Ingestion — 🥉 Bronze Zone
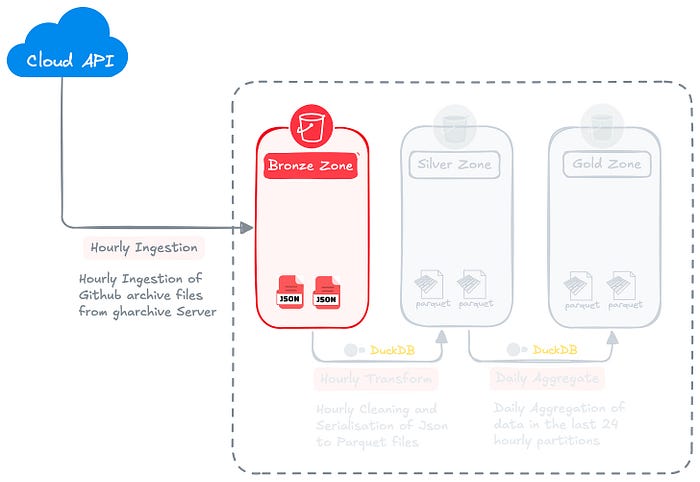
To implement our data ingestion pipeline, we need to identify the interface, protocol and data type of the source system, as this will guide our approach. Here’s the breakdown for this use case:

Based on the above requirements, we need to download hourly JSON compressed files from gharchive.org server over HTTP.
A straightforward approach in Python is to use the requests library to stream and buffer the file from the source, followed by the boto3 library to upload the file to S3, publishing it to the Bronze zone of the data lake.
The Following is a simple example to collect and publish the data:
import requests
gharchive_url = "http://data.gharchive.org/2024-09-01-10.json.gz"
response = requests.get(gharchive_url)
response_content = response.contentData upload to S3:
import boto3
s3_client = boto3.client(
's3',
aws_access_key_id="your-aws-access-key-id",
aws_secret_access_key="your-aws-access-key"
region_name="the-region-name"
)
target_s3_key="gharchive/events/2024-09-01-10.json.gz"
s3_client.upload_fileobj(io.BytesIO(response_content), "datalake-bronze", target_s3_key)While this example is suitable for testing, it’s a basic implementation. To build a robust data pipeline we need to incorporate better parametrisation, error handling, and modularity.
For this, I’ve written a class called data_lake_ingestor.py, which fetches data from the GitHub Archive for a specific hour. It uses Python's requests library to download the compressed JSON file in memory. The data is then uploaded directly to the specified S3 bucket, with the S3 key based on the date and hour.
To execute the ingestion pipeline all we need to do is passing a timestamp to the ingestion method ingest_hourly_gharchive() , which will be used to determine the interval for the JSON file to collect and load from source.
from datetime import datetime, timedelta
from data_lake_ingester import DataLakeIngester
ingester = DataLakeIngester("gharchive/events")
now = datetime.utcnow()
# Calculate the process_date (1 hour before to ensure data availability at source)
process_date = now.replace(minute=0, second=0, microsecond=0) - timedelta(hours=1)
ingester.ingest_hourly_gharchive(process_date)Managing Configurations and Secrets
Configuration settings, such as AWS credentials and bucket names, are stored in a configuration file (config.ini), to keep the code free from any sensitive and static data.
[aws]
s3_access_key_id = your_access_key_here
s3_secret_access_key = your_secret_key_here
s3_region_name = your_region_name_here
s3_endpoint_url = your_custom_endpoint_url_here
[datalake]
bronze_bucket = you_bronze_zone_bucket
silver_bucket = you_silver_zone_bucket
gold_bucket = you_gold_zone_bucketIn the code, we utilise Python’s configparser library to load these configurations into the class, as demonstrated in the private method below.
def _load_config(self):
config = configparser.ConfigParser()
config_path = os.path.join(os.path.dirname(__file__), 'config.ini')
config.read(config_path)
return configRaw Data Serialisation — 🥈 Silver Zone

After ingesting the raw GitHub Archive data into our data lake’s Bronze layer, the next critical step in the pipeline is to clean and serialise this data, preparing it for the Silver layer. This is where DuckDB plays a key role, performing the necessary transformations within the data lake.
The transformation logic is encapsulated in the DataLakeTransformer() class, located in data_lake_transformer.py. This class provides two primary methods: serialise_raw_data() for data cleaning and serialisation, and aggregate_silver_data() for aggregating the data.
Let’s take a closer look at the serialisation logic:
def serialise_raw_data(self, process_date: datetime) -> None:
try:
...
gharchive_raw_result = self.register_raw_gharchive(source_path)
gharchive_clean_result = self.clean_raw_gharchive(gharchive_raw_result.alias)
...
gharchive_clean_result.write_parquet(sink_path)
except Exception as e:
logging.error(f"Error in serialise_raw_data: {str(e)}")
raiseThis method performs several key steps:
Source and Sink Configuration: It determines the source (Bronze) and sink (Silver) bucket names based on the parameters specified in the configuration file (config.ini).
Data Loading: The logic for importing the raw JSON data into an in-memory table using DuckDB’s Relational API is defined in the following method:
def register_raw_gharchive(self, source_path) -> duckdb.DuckDBPyRelation:
self.con.execute(f"CREATE OR REPLACE TABLE gharchive_raw \
AS FROM read_json_auto('{source_path}', \
ignore_errors=true)")
return self.con.table("gharchive_raw")The method returns a duckdb.DuckDBPyRelation object, which acts as a relational reference to the in-memory table. This ensures that subsequent steps operate on the in-memory data, avoiding repeated reads from the source file.
A key detail here is the ignore_errors=true parameter. DuckDB infers the schema from the first few records, and in the case of large datasets with inconsistent schemas (e.g., extra nested attributes in some records), errors may occur.
By setting ignore_errors=true, DuckDB skips over records that don’t match the inferred schema, which is efficient for our use case, where we don’t need deep, optional attributes found in some records. Alternatively, we could scan more records or provide an explicit schema, but that would introduce significant overhead for the large files we are processing.
Data Modeling
Before we serialise the raw data into Parquet format we need to perform a data modeling exercise and only select the attributes we are interested in. For this we can use DuckDB SQL to implement the data modeling logic as shown in the following method.
The result of the SQL query encapsulated in the method below, is also stored in an in-memory table, ensuring that multiple future calls do not re-execute the SQL logic.
def clean_raw_gharchive(self,raw_dataset) -> duckdb.DuckDBPyRelation:
query = f'''
SELECT
id AS "event_id",
actor.id AS "user_id",
actor.login AS "user_name",
actor.display_login AS "user_display_name",
type AS "event_type",
repo.id AS "repo_id",
repo.name AS "repo_name",
repo.url AS "repo_url",
created_at AS "event_date"
FROM '{raw_dataset}'
'''
self.con.execute(f"CREATE OR REPLACE TABLE gharchive_clean AS FROM ({query})")
return self.con.table("gharchive_clean")DuckDB offers powerful features for working with nested JSON files, such as those found in the GitHub Archive dataset. One of the key advantages is the ability to use dot notation to access nested attributes directly, as well as functions like unnest() to fully unpack nested structures in your queries.
For example, if we wanted to flatten and extract all the attributes within the actor object, we could do so with a simple query like:
query=f"SELECT UNNEST(actor),.... FROM '{raw_dataset}'"This approach makes it easy to work with complex, deeply nested data while maintaining simplicity in your queries.
Data Export: After the data has been cleaned, the result is written to the Silver layer in Parquet format using DuckDB’s engine:
gharchive_clean_result.write_parquet(sink_path)Serialisation Performance
When running the serialisation process close to the data, and using DuckDB to handle the transformation, the entire process completes in under a minute.
This efficiency makes DuckDB an excellent choice for lightweight, in-place data transformations, especially when working with local or cloud-based object storage systems like S3.
2024-10-01 15:41:04,365 - INFO - DuckDB - collect source data files: s3://datalake-bronze/gharchive/events/2024-10-01/15/*
100% ▕████████████████████████████████████████████████████████████▏
2024-10-01 15:41:29,892 - INFO - DuckDB - clean data
2024-10-01 15:41:30,129 - INFO - DuckDB - serialise and export cleaned data to s3://datalake-silver/gharchive/events/2024-10-01/15/clean_20241001_15.parquet
100% ▕████████████████████████████████████████████████████████████▏Key Takeaways
The use of DuckDB for this transformation process is a key design choice:
- In-Memory Processing: DuckDB allows for efficient in-memory processing of the data, which is particularly useful for the typically large GitHub Archive datasets.
- SQL Interface: The use of SQL for data modeling provides a familiar and powerful interface for data transformations.
- Parquet Writing: DuckDB has very efficient Parquet reader and writer for fast and efficient serialisation of data from primitive data types such as JSON and CSV, while eliminating the need for intermediate steps or additional libraries.
Data Aggregation — 🥇 Gold Zone
After modeling and serialising our GitHub Archive raw data into the Silver zone, the next step in our data pipeline is to aggregate this data and publish it to the Gold zone on daily basis.
Here’s an overview of the method responsible for performing the daily aggregation:
def aggregate_silver_data(self, process_date: datetime) -> None:
try:
...
gharchive_agg_result = self.aggregate_raw_gharchive(source_path)
...
gharchive_agg_result.write_parquet(sink_path)
except Exception as e:
logging.error(f"Error in aggregate_silver_data: {str(e)}")
raiseThis method encompasses several key steps:
Source and Sink Configuration: It identifies the source (Silver) and sink (Gold) bucket names based on the configuration.
Data Loading and Aggregation: The aggregation logic is defined by using SQL applied to a DuckDB virtual table that has been defined over Parquet files present in the Silver zone. This aggregation focuses on counting GitHub events by type (e.g., stars, pull requests), repository, and date, providing an aggregated view of GitHub activity within a daily time window.
def aggregate_raw_gharchive(self, raw_dataset) -> duckdb.DuckDBPyRelation:
query = f'''
SELECT
event_type,
repo_id,
repo_name,
repo_url,
DATE_TRUNC('day',CAST(event_date AS TIMESTAMP)) AS event_date,
count(*) AS event_count
FROM '{raw_dataset}'
GROUP BY ALL
'''
self.con.execute(f"CREATE OR REPLACE TABLE gharchive_agg AS FROM ({query})")
return self.con.table("gharchive_agg")The GROUP BY ALL feature in DuckDB simplifies group by statements by removing the need to explicitly specify the columns.
As with the previous transformation step, we persist the result of this aggregation to an in-memory DuckDB table, returning it as a DuckDBPyRelation object to ensure that future calls do not re-execute the SQL logic.
Data Export: The aggregated data is subsequently written to the Gold zone in Parquet format:
gharchive_agg_result.write_parquet(sink_path)Aggregation Performance
The transformation pipeline on a cloud VM takes less than a minute to aggregate 24 Parquet files containing nearly 6 million records, and serialise the result into a Parquet file published in the Gold zone.
This efficiency underscores the capability of DuckDB to handle small to medium-scale data transformations quickly and effectively.
2024-10-01 00:31:42,787 - INFO - DuckDB - aggregate silver data in s3://datalake-silver/gharchive/events/2024-10-01/*/*.parquet
100% ▕████████████████████████████████████████████████████████████▏
2024-10-01 00:31:53,020 - INFO - DuckDB - export aggregated data to s3://datalake-gold/gharchive/events/2024-10-01/agg_20241001.parquet
100% ▕████████████████████████████████████████████████████████████▏Key Takeaways
The use of DuckDB for this data aggregation process offers several advantages:
- Efficient Processing: DuckDB’s column-oriented storage and processing is well-suited for analytical queries and aggregations.
- SQL Interface: The use of SQL for aggregation in Python provides a familiar and powerful interface for complex data transformations.
- Efficient Parquet Integration: DuckDB’s native support for Parquet files allows for efficient reading and writing of data in this format.
Orchestration & Scheduling
In a production environment, you would typically use a workflow orchestrator like Apache Airflow, Dagster or Prefect to manage the execution of the three pipelines discussed in this article.
However, since the goal here was to demonstrate how DuckDB can be used for data transformation, I’ve intentionally omitted any external orchestration or scheduling components. Instead, in the GitHub project, I’ve provided individual scripts for each pipeline along with instructions in the README on how to schedule them easily using cron.
That said, you can easily adapt the code to your preferred workflow orchestrator. For example, in Airflow, you could use a PythonOperator to call the functions for each pipeline step by importing the relevant class.
This code-first approach to pipeline development ensures that your business logic remains decoupled from workflow logic, making the pipelines flexible and easy to port to any Python-based orchestration tool.
Interactive Data Analytics
Once the data is prepared for analytics, DuckDB’s efficient querying capabilities allow us to easily extract meaningful insights from the aggregated data, making it an excellent tool for interactive data analysis.
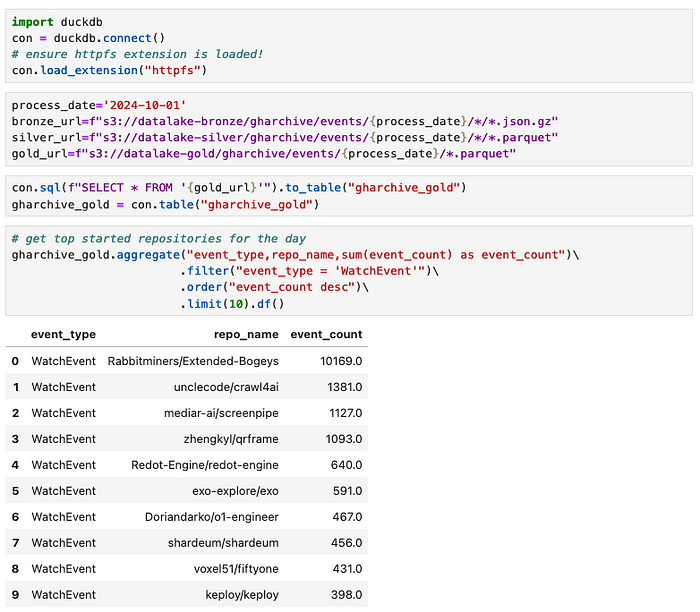
Following code snipped from a Jupyter notebook on my laptop demonstrates how to analyse the most-starred repositories on a specific day using the Parquet files stored in the Gold zone.
The code showcases DuckDB’s Python API, highlighting its Pythonic data analysis capabilities, which are comparable to other DataFrame APIs like PySpark and Pandas.
In this article, we explored how DuckDB can be leveraged for efficient batch data transformation and serialisation in a data lake architecture. We walked through the steps of ingesting raw GitHub Archive data, transforming it into structured formats, and aggregating the data for analysis using Medallion architecture (Bronze → Silver → Gold).
DuckDB’s in-memory processing, SQL-based transformation capabilities, and seamless Parquet integration make it an excellent choice for handling such datasets with high performance.
For those looking to replicate this approach, the full code examples are available on GitHub, allowing you to explore the potential of DuckDB in your own data transformation pipelines.
Subscribe to my Practical Data Engineering newsletter to get exclusive early access to my latest stories and insights on data engineering.
