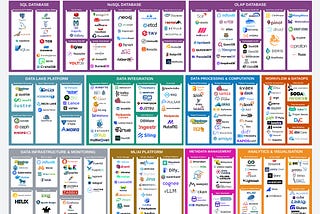
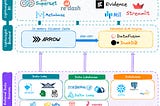
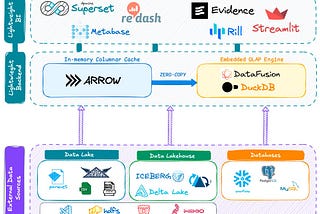
PinnedOpen Source Data Engineering Landscape 2025A comprehensive view of active open source tools and emerging trends in data engineering ecosystem in 2024–2025Feb 1212Feb 1212
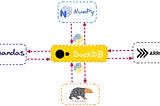
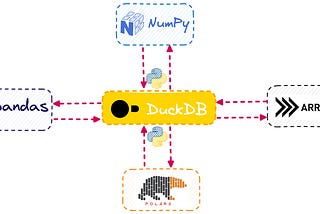
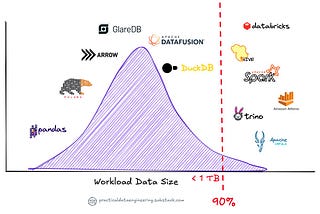
PinnedDuckDB Beyond the HypeA Powerful Addition to the Data Scientist’s and Data Engineer’s ToolboxSep 18, 20243Sep 18, 20243
PinnedOpen Source Data Engineering Landscape 2024Exploration of the open source software in data engineering ecosystemFeb 4, 202417Feb 4, 202417
The Rise of Single-Node Processing: Challenging the Distributed-First MindsetData Landscape Trends: 2024–2025 SeriesJan 295Jan 295
The Evolution of Business Intelligence: From Monolithic to Composable ArchitectureData Landscape Trends #1: 2024–2025 SeriesJan 233Jan 233
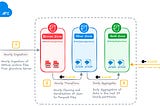
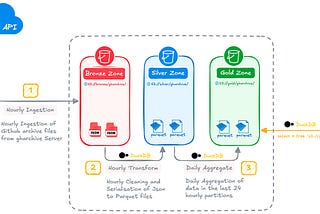
Building a High-Performance Data Pipeline Using DuckDBUsing DuckDB to Serialise, Transform, and Aggregate Data in Data LakesOct 20, 20243Oct 20, 20243
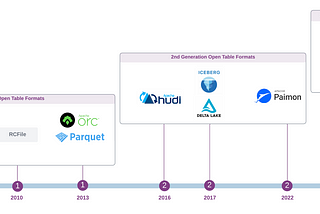
The History and Evolution of Open Table FormatsFrom Hive to High Performance: A Journey Through the Evolution of Data Management on Data LakesAug 23, 2024Aug 23, 2024
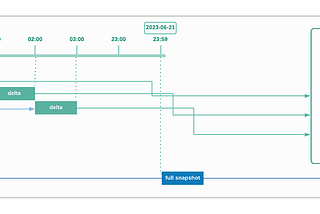
How to build a dual Incremental + snapshot data ingestion pipelineA useful batch data ingestion pattern for maximum data correctness and reliability as well as providing low latency accessOct 1, 2023Oct 1, 2023
Techniques For Periodically Extracting Data From Relational DatabasesPresenting techniques for extracting data from relational databases when building ETL pipelines for a data lake, DWH or data lakehouseSep 19, 2023Sep 19, 2023
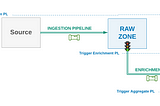
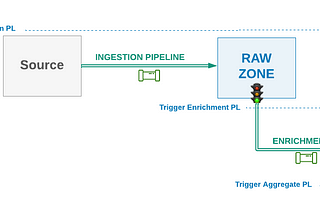
Techniques for Managing Dependency Between Data PipelinesIt’s a common challenge to manage dependency between data pipelines on data-driven systems and analytical platforms which having data…Aug 29, 2023Aug 29, 2023